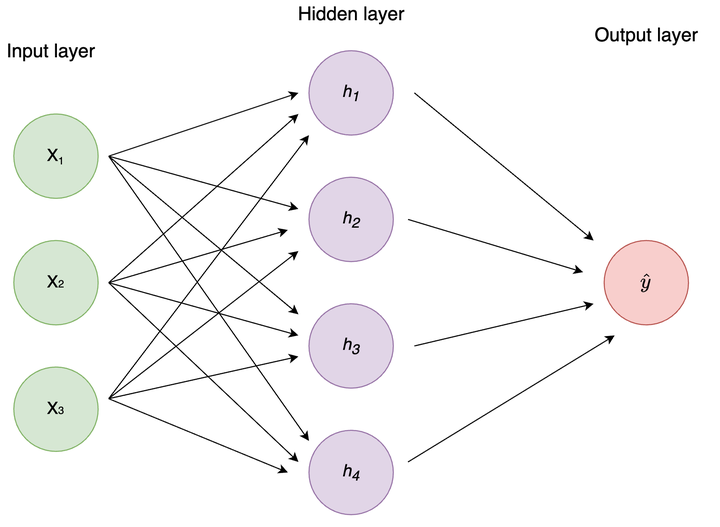
Neural Networks from Scratch (without linear algebra)
Lasse Hansen
PhD Student in Machine Learning for Healthcare
I am a PhD student at the Department of Clinical Medicine at Aarhus University studying how to use machine learning to improve patient outcomes in psychiatry. In particular, my focus is on applying methods from Natural Language Processing to electronic health records for early prediction of schizophrenia and bipolar disorder.