A generalizable speech emotion recognition model reveals depression and remission
Abstract
Objective: Affective disorders are associated with atypical voice patterns; however, automated voice analyses suffer from small sample sizes and untested generalizability on external data. We investigated a generalizable approach to aid clinical evaluation of depression and remission from voice using transfer learning. We train machine learning models on easily accessible non-clinical datasets and test them on novel clinical data in a different language.
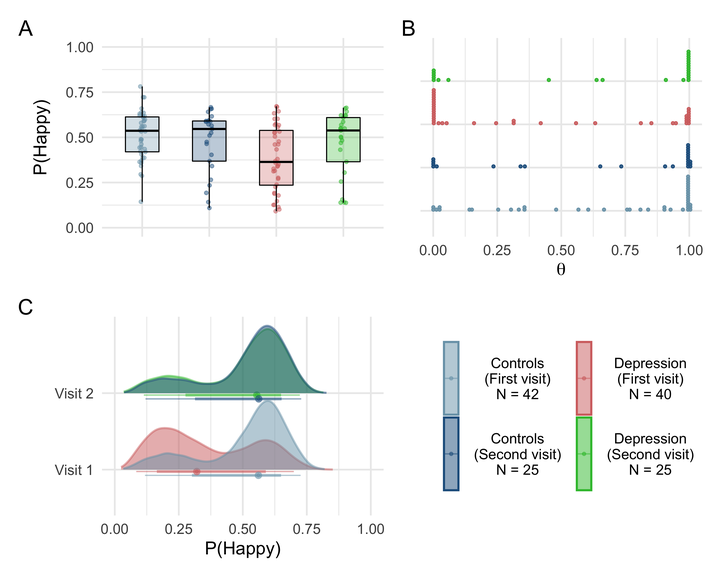
Methods: A Mixture of Experts machine learning model was trained to infer happy/sad emotional state using three publicly available emotional speech corpora in German and US English. We examined the model’s predictive ability to classify the presence of depression on Danish speaking healthy controls (N = 42), patients with first-episode major depressive disorder (MDD) (N = 40), and the subset of the same patients who entered remission (N = 25) based on recorded clinical interviews. The model was evaluated on raw, de-noised, and speaker-diarized data.
Results: The model showed separation between healthy controls and depressed patients at the first visit, obtaining an AUC of 0.71. Further, speech from patients in remission was indistinguishable from that of the control group. Model predictions were stable throughout the interview, suggesting that 20–30 s of speech might be enough to accurately screen a patient. Background noise (but not speaker diarization) heavily impacted predictions.
Conclusion: A generalizable speech emotion recognition model can effectively reveal changes in speaker depressive states before and after remission in patients with MDD. Data collection settings and data cleaning are crucial when considering automated voice analysis for clinical purposes.
Lasse Hansen
PhD Student in Machine Learning for Healthcare
I am PhD student at the Department of Clinical Medicine at Aarhus University. I study how to use natural language processing and machine learning to improve patient outcomes in psychiatry. I am broadly interested in applying machine learning to solve real world problems, and in advancing open-source software.